



競プロ日記000: ABCはじめました
ABC(AtCoder Beginner Contest)に初参加しました
以前から気になっていたもののスケージュールの都合とか体調の問題で参加を見送っていましたが,重い腰をついに上げユニークビジョンプログラミングコンテスト2022 夏(ABC268)に参加しました.理由は2つあって,1つは単純に「参加している人たちが楽しそう」ということ,もう1つは「ヒューリスティックコンテストの実力を強化したい」ということです.
概要
私はABC初参加とはいえヒューリスティック系のコンテストにはそこそこ参加していて,今年(2022年)の春ごろからATopCoder MM(Marathon Match)やAHC(AtCoder Heuristic Contest)のようなヒューリスティック系のコンテストには好んで参加しています.AtCoderでのヒューリスティックレーティングは現状こんな感じ(1337の水色)です.

MMのコンテスト期間は基本的に1週間で,AHCの場合は1~2週間の場合と4時間だけの場合があります.特に4時間制限のコンテストでは今までまともな成績で終われた経験がなく,短期間で解答を完成させることがなかなかできませんでした.そこで「瞬発力を上げよう!」という考えに至ったわけです.つまり本稿はヒューリスティックでもっと強くなりたいオッサンが瞬発力を上げるトレーニングとして短期コンテストに参加するという日記であります.最初は問題の具体的な解法とかコードを中心に書いていこうかと思ったんですが,今は公式な解説があるのと,非公式で多くの方が有用な記事をたくさん書いてらっしゃるので,この辺りはあまり書かないつもりです(余程解説と異なる場合等は書くかも).
はじめて参加した感想
これから競プロを始める人や将来の自分に向けて,気付いたこと等をまとめておきたいと思います.
解答順序
問題のレベル感が全くわからないので,素直にA,B,C,…の順番に解きました.基本的には全部で8問みたいなので,5~6問くらい解けるレベルになってくると取り掛かる問題の順序は考えなければならないかもしれません.当面はAから順に解く方針でいくのが無難かと思いました.
言語の選択
AとBはPython3で解いて,CでTLE(時間制限)に引っかかる問題が出てきたので念のためC++に変えました.おそらく想定解のアルゴリズムではPythonでも十分なのだろうと思うので全部Pythonでも良いかなーと思いつつ,無理やりC++でチューニングしたコードで上手くいく可能性があるかもしれないので,ちょっとよくわかりません.これは何回か参加しながら自分にとって最適な選択を見つけるのが良さそうです.
ローカルテスト
AtCoderではヒューリスティックしか参加したことが無かったので,不正解のコードを提出するとペナルティがあるのをすっかり忘れていました.C問題では愚直にやればO(N2)くらいかー,TLEになりそうだなー,とりあえず提出→TLE→やっぱり😅→ペナルティ→えぇ😱
今回は大きなテストケースを自分で作って確認してから再提出したのですが,おそらくこれは(競プロ的には)良くない方法で,入力の範囲から計算量をできるだけ正確に見積もって,どれくらいのオーダーで解けば良いかを掴めるようになっていなければならないのではと思います.
ソースコードやテストケースの生成
問題が複数あるので,新しく問題を解く際に新規のソースコードとかテストケースのファイルを用意しなければなりません.今回はこの辺をあまり考えてなかったので,問題Aを解くときにAというディレクトリを作って,問題Bを解くときはAを複製してリネームみたいな感じでやっていました.こうすると,CとかDあたりで焦りが出てきたときにかなりワタワタしてしまって,編集ミスとか提出ミスをしやすそうです.しっかり手順を決めておくとか,ある程度自動的に処理できるようにスクリプトを事前に用意するとかしておくと良さそうです.
結果
初参加の結果は,ABCの3問が通って,Dのコードを実装中に時間切れになりました.Dは完成させてから提出すると通ったので,もう少しスピードアップすれば大丈夫そうかなといったところです.

というわけで初参加の結果,レーティングが55になりました.レーティングに関しては何もわかってないですが,
固定で引かれる数がある(回数を増やすとこの数は減る)ので最低10回は出ないと正しい数値は出ないです
— しえる@codefes2016::002 (@cielavenir) 2022年9月11日
とのことで,最初の数回は少々ひどい結果でも参加さえしていればいくらかは上がっていきそうです.
次回に向けて
過去問とかやれば良いだろうなーとは思いますが,まずABCに参加する時間を捻出すること自体が大変なのと,前述の通り何回も参加してレーティングを上げていく必要があるみたいなので,当面は特に準備せず参加をしていきたいと思います.10回くらい参加したところで現時点での自分の実力が大体わかりそうなので,その頃に次の対策を考えるのが良さそうですね.
競プロ本の新刊!!
この日記をダラダラを書いている最中に,1冊の本が届きました.
")
マイナビ様本当にありがとうございます.もうちょっと頑張って仕事します😅
パラパラと中を見た結果明らかに素晴らしいものだと思ったので,近いうちに紹介の記事を書かせていただきます.
次回に向けて(修正)
基本的には前述のとおりですが,良い本を頂戴しましたので『競技プログラミングの鉄則』を読んで勉強しつつ進めることにします.
何が何でもTopを取りたかった話(1)
はじめに
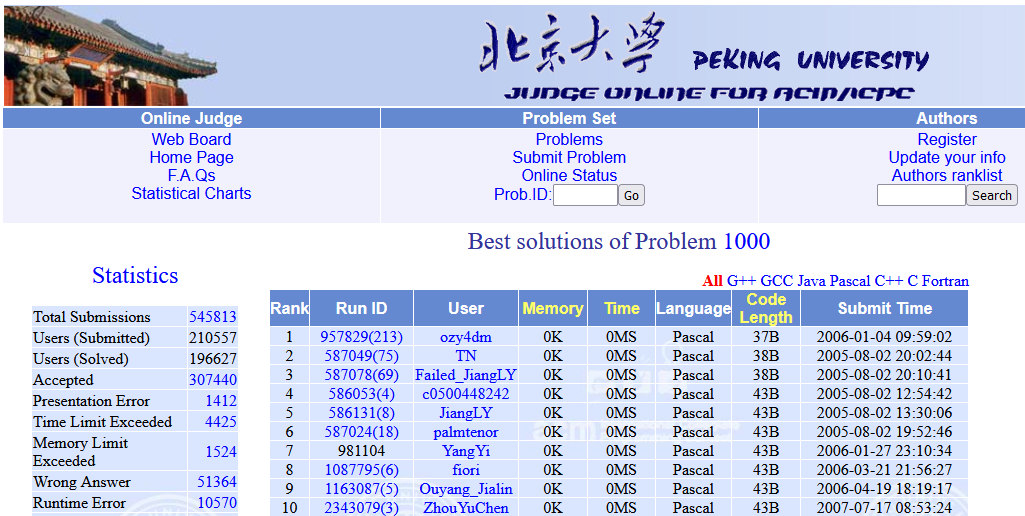
この問題は非常に単純なもので,2つの整数値を読み込んでそれらの和を出力するだけの問題です.2022年4月5日14時現在では提出数545364・そのうち正解数307448と,これまでにどれだけのユーザが利用したか想像できると思います.この画像の一番上にあるozy4dmというidは私のものです.2006年1月から,少なくともこの記事を公開するまでずっと一番上にあります.
問題の内容からして小学生でも解けるレベルの問題で一番上を目指すなんて,ほとんど無意味でバカみたいなことかもしれませんが,「じゃあやってみろ」と言われて実際にできるのかというと結構難しい話です.わかる人はバカらしくてやる気にならないだろうし,わからない人にとってはものとても難しいでしょうから.
この記事は,そんなしょうもなさそうな目標を達成した,2005~2006年ごろ(今から16~17年くらい前)のお話です.これがどれくらい昔かというと,目指せ!プログラミング世界一―大学対抗プログラミングコンテストICPCへの挑戦 という,本格的な競技プログラミング書籍が発行されたのが2009年,プログラミングコンテストチャレンジブック [第2版] ~問題解決のアルゴリズム活用力とコーディングテクニックを鍛える~ (通称「蟻本」)と呼ばれる競技プログラミングのバイブル(初版)の発行が2010年ですので,それよりもっと前の話ということですね.(ちなみに最強最速アルゴリズマー養成講座 プログラミングコンテストTopCoder攻略ガイド の発行が2012年,プログラミングコンテスト攻略のためのアルゴリズムとデータ構造 が2015年の発行です.)
背景
背景と言っても,競技プログラミングには全く縁のなかった私ですので,一般的な背景ではなく単なる私の背景です.当時ACM-ICPCのようなプログラミングコンテストの存在を全く知らず,オンラインジャッジのサイトも単なる遊び場でした.今でこそいろいろと知識や技術を習得しましたが,当時はBFSとかDFSのような基本的なアルゴリズムも知りませんでしたし,解くことのできる問題が限られていました.
一応勉強のために,ある程度難しい問題にも挑戦していましたが,大半は比較的簡単な問題を解いて,その後ソースコードを短くする,いわゆるコードゴルフと呼ばれる遊びをしていました.これが本当に楽しくて一生遊べます.どれくらい楽しかったかというと,それだけで本を1冊書くくらいです.
もちろんPOJはコードゴルフをするためのシステムではないので,勝手に遊んで運営の方にも結構迷惑をかけていましたが….
Topに立つってカッコええやん?
さて最初の画像の話に戻りますが,オンラインジャッジのサイトにアクセスして,おそらくほとんどすべてのユーザが最初に開く問題は,一番最初に設置された問題だと思います.POJでは問題のレベルやタイプの分類はされていませんでしたから,とりあえず問題一覧を開くと最初の問題が一番上に表示されました.
このとき私は思ったのです.「ここのStatusで一番上に表示されてたらカッコ良くね?」と.
一番上に表示されるために必要なこと
POJの(問題毎の)Status表示では,表示する際の順序として
- プログラムの実行時間
- 消費メモリ
- ソースコードのサイズ
- 提出の日時
の優先順位でソート昇順にされています.プログラムの実行時間はかなり大雑把(たぶんclock関数とか使ってる?)で,この問題は基本的に0msで通ります.つまり実行時間の面では先に提出した人が有利で,ここで差をつけることはできません.
消費メモリ
POJの消費メモリ測定は(も)かなり大雑把です.詳細は知らないのでこれから書くことはシステムの挙動から推測した内容です.概ね正しいと思いますが,このセクションはすべて「おそらく」を補って読んでください.
POJのシステムは内部でWindows APIを使って消費メモリを取得していましたが,その値をそのまま使用していませんでした.これは言語間での差異を無くすための処置だと思います.事前に各言語で空のプログラムを実行して消費メモリを測定しておき,提出されたプログラムを実行したときの消費メモリから差し引く処理を行っていました.
APIから取得できる消費メモリのサイズは割とアバウトで,大きな配列のような,ある程度大きなサイズのメモリを消費する際はそれらしい値になりますが,ほとんどメモリを消費しないプログラムの場合,誤差の大きい記録になっていました.
空プログラムの消費メモリは毎回測定しているわけではなく,システムのリブート時とか特定のタイミングでしか行われていないようなので,消費メモリのサイズが大きい日が続いたり,小さい日が続いたりということがあり,ひどいときは負の値になっていることもありました.
私はここに目をつけて,消費メモリが負の日に提出することを試みましたが,データベースには絶対値を記録しているようで,ちょうど0にならなければならないことがわかりました.また,ほとんどの言語では消費メモリのサイズが0になることはめったになく,Pascalだけがその確率が大きいことも発見しました.
この時点で残された選択肢は,「消費メモリがちょうど0になる日に,Pascalで最短のコードを通す」ことになりました.2005年の12月から2006年の1月4日まで,毎朝起きるとすぐに他のユーザの提出状況をチェックして消費メモリの補正値を確認していました.
最短のPascalコード
よくよく考えると,このコードを公開していなかった気がしてきたので,ここで晒しておきます.どうぞ皆さん幻滅なさってください笑

ここからおまけの話
この記事を書こうと思ったきっかけは,Twitterで「他人のコードをコピペするなんて!」みたいなツイートをちょいちょい見かけたからです.良いとか悪いとかは正直言えません.でも,当時POJがソースコードを原則公開するようなものだったら自分はどうしていただろうなぁと思ってしまったので,思いついたことをたらたらと書いておきます.
コードの公開
最近では,競技プログラミング的なコードは積極的に公開されるようになりました.そのおかげでプログラミングの学習効率は飛躍的に上がった気がします.当時は基本的に非公開だったので,提出したコードを自分のブログなどで公開したり解説するだけで,ある程度価値のある記事にすることができました.しかしコードの公開は,それなりにリスクを負うことになります.
それは自分の公開したコードをちょちょいと改変して,トップを獲られてしまうことです.実際,「最短コードやで!どや!!」みたいな記事を書いた直後に記録を抜かれることなんていくらでもありました.
でも,ほとんどのケースでは,自分のコードをちょっと弄ったというわけではなくて,新しいテクニックとか私では思いつかないような賢い方法で抜かれただけなので,気にする程のことは無かったように思います.たとえば余計なスーペースとか改行,使わない変数の消し忘れとか,そんな初歩的なミスでトップを獲られるなら,それは詰めの甘い自分が悪いだけですしね.
もちろん,自分が苦労して書いたコードを丸パクリとか,ちょっと変えただけで自分より良い成績を取られるのはとても悔しいことです.理想はさらに良いコードを書くことですが,うまくいかないことの方が多いと思います.おそらく自分が当事者になったら,パクリ合戦でもなんでも,相手が逃げ出すまでやると思いますが.
そこまでの執着心がなければ,さっさと次のお題に移って自分のスキルアップを目指した方が良いでしょうね.今競技プログラミングをしている人たちは,本当に高い能力を具えているように見えます.1つの問題に固執してチマチマチマチマやるのは私に任せて,どんどん上を目指して欲しいですね.
コードゴルフの文化
最近は,純粋にコードゴルフをする人はAnarchy Golfを利用しています.ここではユーザ登録の必要がなく,単に投稿者を識別するためだけの名前と,あとはソースコードのみを投稿します.また,ほとんどの問題では一定の期間を過ぎればソースコードが公開されます.
ソースコードが非公開の間は,ソースコードのサイズが小さい順,同サイズの場合は提出の早い順で順位が決まります(特殊なルールの問題を除く).ソースコードが公開された後,よりサイズの小さいコードを提出したとしても,それは後日の記録ということでランキングの下に追加されるようになっていて,よく考えられています.
しかしそれだけではなく,他人のコードから着想を得た場合に自分の名前+誰のアイデアを利用したかのような情報を付与するコードゴルファーは少なくありません.ルールではなく,暗黙のルールとかマナーというほどのものでもなく,なんとなく自然に行われていることです.
POJで遊んでいた頃でも,誰かが公開したコードがさらに短くなるとわかったとき,コメントで指摘するとか,自分で提出する場合でも余計に改行を入れて記録を抜いてしまわないように配慮する人だけが残るようになっていきました(もちろん新しいアイデアが閃いたときは容赦なく記録を更新しますが).
これって皆が真剣に遊んで,自然にそうなっただけなんですよね.別に誰かから強制されたこともないですし,長い年月を経てそうなっただけ.
もちろん今後,システムとか他の利用者に迷惑をかけたり,それまでとは異質な人間が入り込んでくることは何度もあると思います.でも,全く心配はしていません.最終的にはちゃんとイイ感じになります.
最後に
まあつべこべ言わずにコードを書けっちゅうことやな(`ω´) 第2回はものすごくモチベーションが高まったら書きます.N年後くらいかな.
POJ3786: 隣接するビットを数えよう(ゴルフあり)
隣接するビットを数えよう
はじめに
この記事は、北京大学のオンラインでプログラミングの問題を解くサービスPKU JudgeOnline(POJ)の問題をピックアップし、解法の解説と、C/C++/Python等による実装例に加えて、少し短いCでの実装を紹介します。後半は完全に趣味の世界ですのでご注意ください。
本稿の構成
問題の説明
引用元
元はACM Regional Collegiate Programming Contest のF問題です。
問題内容
ビット列(0と1の並び)の中に、隣り合う1が何組あるかを答える問題です。入力はビット列の長さと、隣り合う1が何組あるかを表す数です。 例えば、"01101100"というビット列には、ビット列の長さが8で隣り合う1が2組あります。"0011100"なら、ビット列の長さは7で、隣り合う1の数は2と数えます。1が3つ並んでいる部分は、左2文字分で1組、右2文字分で1組の合計2組ということです。"1111"というビット列なら、隣り合う1は左2文字、中央2文字、右2文字の合計3組と数えます。つまり、1がx個連続していれば、隣り合う1の組みは(x-1)あるということです。
ビット列の長さ(n)は最大100で、隣り合うビットの組(k)はそれより少なくなります。条件としてnとkが与えられたとき、条件を満たすようなビットの並びは何通りあるかを計算して出力してください。
というような問題です。
入力例
以下のように、最初にテストケースの数が与えられ2行目以降に「テスト番号」「ビット列の長さ」「隣り合う1の組数」が空白文字で区切られています。
10 1 5 2 2 20 8 3 30 17 4 40 24 5 50 37 6 60 52 7 70 59 8 80 73 9 90 84 10 100 90
出力例
出力は、「テスト番号」「条件を満たすビットの並びの総数」を空白文字で区切り、各テストケースごとに改行します。
1 6 2 63426 3 1861225 4 168212501 5 44874764 6 160916 7 22937308 8 99167 9 15476 10 23076518
具体例
入力例の1つ目のテストケースでは、nが5でkが2です。このとき考えられるビットの並びは、 11100, 01110, 00111, 10111, 11101, 11011 となっているため、出力の1行目には6と出力されます。
アプローチ
長さnのビット列を全て列挙し、隣り合うビット列をカウントする方法は、自分で小さなテストケースを作成するのに良い方法ですが、それをそのまま解答とすることはできません。ビット列の長さは最大100もあるので、100ビット整数、つまり2100(=1267650600228229401496703205376)通りも調べなければならず、現実的ではありませんね。
DPによる解法と実装例
概要
隣り合う1の組を単純に数えるには非常に時間がかかりますし、テストケースも複数あります。一度数えたビット列に対して何度も数えなおさず済むように数を記録し、さらに長いビット列を調べる場合にそれを利用できるようにします。
表記方法
ビット列の長さをn、そのビット列に含まれる隣り合う1をk組とするときのビットの並びの総数をf(n, k)と表します。
準備
まず、長さ1のビット列を考えます。長さ1のビット列は、"0"と"1"の2通りありますが、隣り合うビット列は2文字以上並んでいないと数えられませんので、いずれの場合も隣り合う1は0組と考えます。
長さ2のビット列は、"00", "01", "10", "11"の4組ですが、この中で1が並んでいるのは"11"の1つだけで、それ以外の3つは0組です。この場合、f(2, 1) = 1, f(2, 0) = 3のように表すことができます。
長さ3まで見てみましょう。この場合は、"000", "001", "010", "011", "100", "101", "110", "111"の8通りで、f(3, 2) = 1, f(3, 1) = 2, f(3, 0) = 5となっています。
数え方を検討する
ビット列の長さが4, 5, 6, ...となると全部書き出すのは少し大変になってきますので、そろそろ数え方のルールを考えるときです。長さ4のビット列は全部で16通りありますが、それは長さ3のビット列8通りのそれぞれに対して、「先頭に0をつけたもの」と「先頭に1をつけたもの」の各8通りを合わせたものです。
このとき、先頭のビットに0をつけたものでは隣り合う1の組は増えませんが、先頭のビットに1をつけた場合は隣り合う1の組が1つ増える可能性があります。たとえば、"011"の先頭に1をつけたものは"1011"で隣り合う1の組は増えていませんが、"110"の先頭に1をつけた場合は"1110"となって、隣り合う1の組みが1から2に増えます。ここに着目すると、計算のルールが決められるはずです。
2種類のテーブルを用意する
ビット列の先頭に0を加えた場合は変化なしとして、1を加えた場合は隣り合う1の数が変化する可能性があるということを確認しました。変化するのは、1を加える前のビット列の最上位ビットが1の場合のみです。つまり、ビット列を次の2つのグループに分けて扱えば良さそうです。
最上位ビットが0のビット列(dp0)
最上位ビットが1のビット列(dp1)
これらについて、ビット列の長さnと隣り合う1の組数kをキーとするビット列の順列数を保持するテーブルを作成しておけば、f(n, k) = dp0[n][k] + dp1[n][k]のような計算で解が得られます。
各テーブルの更新方法
最上位ビットに0を加えたものは隣り合う1の組数が変わらないので、
dp0[n + 1][k] = dp0[n][k] + dp1[n][k]
で得られます。最上位ビットに1を加えたものは、
dp1[n + 1][k] = dp0[n][k] + dp1[n][k - 1]
のように計算します。dp1の添え字に注意してください。
実装例
以上の方法でPythonのコードを書いてみました。
import sys # 問題がのサイズが最大100なのでそれに合わせた二次元配列 # dp[k][-1]で番兵にアクセスできるように実際のサイズはNより大きく N = 100 SIZE = N + 2 dp0 = [[0] * SIZE for i in range(SIZE)] # 最上位ビットが0のビット列用 dp1 = [[0] * SIZE for i in range(SIZE)] # 最上位ビットが1のビット列用 dp0[1][0] = 1 dp1[1][0] = 1 def make_dp(): for i in range(N): for j in range(i): dp0[i + 1][j] = dp0[i][j] + dp1[i][j] dp1[i + 1][j] = dp0[i][j] + dp1[i][j - 1] dp1[i + 1][i] = 1 def solve(n, k): return dp0[n][k] + dp1[n][k] # テストケースの数 n_test = int(sys.stdin.readline()); make_dp() for line in sys.stdin: tid, n, k = list(map(int, line.split())) print(f"{tid} {solve(n, k)}")
オリジナルの問題ではビット列の長さの上限が100ですので、それを定数にしています。また、Pythonではリストの添え字に-1を使うことでリストの最後尾にアクセスできることから、リストの最後尾に0を置いてループ内のコードがシンプルになるようにしています。
組み合わせ計算による解法と実装例
次は、任意のnとkに対して直接計算する方法を考えてみましょう。
はじめに
DPの場合と違って、ある程度大きなサイズのビット列で考えます。あまりに小さな例だと誤解する可能性があるからです。というわけで、まずはn=10, k=5くらいで考えてみましょう。この条件を満たすビット列の中で、ビット列に含まれる1の数が最も少ないのは"0001111110"のような、1が6つ連続し、他がすべて0であるような場合です。
少し一般的に言えば、長さnのビット列の中に含まれる1は少なくとも(k + 1)個あるということになります。では、ここから1の数を増やす操作を考えてみましょう。"0001111110"の"0"の部分を1に置き換えると、"1001111110"や"0101111110"は問題ありませんが、"0011111110"や"0001111111"の場合はkの値が変化してしまいます。kの値を増やさずにビット列の中の1を増やすには、どうすればよいでしょうか。
ビット列の分割(その1)
先の例を引き続き用いて、kの値、つまり隣り合う1の組数を変えずにビット列の1を増やすことを考えてみます。まずは1の並びが最小数6であるビット列"111111"に1を追加する方法を検討します。このビット列には、最上位ビットにも再開ビットにも1を加えるとkが増加してしまいますが、元のビット列のどこかに0を挿入すると、kの値は変化しません。例えば"111111"の中央に0を挿入してみると、"1110111"となります。このとき、隣う1の組は左側も右側もそれぞれ2になり、合計値すなわちkの値は2+2=4になります。さらにこのビット列の左右に1を加えると"11110111", "11101111"のようになり、いずれの場合もk=5をキープできます。
"0"を1つ挿入して左右のどちらかに"1"を付け加えるという操作であることは間違いないのですが、計算上は少しややこしいので、先に"1"を付け加えてから0を挿入すると考えます。そうすると、分割後に"1"を加える操作まで含めて6通りあるということになります。
今度は全体のビット長をnにするため"0"を補います。"0"を補っても良い箇所は、最初に"0"を挿入した部分と、左右両端の三か所です。
現時点でビット列の長さは8なので、あと2文字分の"0"を、左|中|右のどこかに挿入します。これは"00||"の並び方に相当し、C(4, 2) = 6という計算(Cは組み合わせの計算)で得られます。"11110111"に"0"を2つ挿入する場合、
0011110111 0111100111 0111101110 1111000111 1111001110 1111011100
のように、確かに6通りありました。 以上をまとめると、まず"1"の並びに"1"を1つ追加し、隙間に0を挿入する場合が6通りあって、それぞれの場合に残った"0"2つ分を挿入する場合が6通りあるので、全部で6*6=36通りあることになります。
ビット列の分割(その2)
では次に、元の"1"のビット列"111111"に、"1"を2つ付け加えることを考えてみます。先と同じように、"1"を2つ付け加えて"11111111"(1が8個)として0を2か所(同じ場所は×)に挿入し、"1"を並びを3分割してみます。このときの分け方は、C(7, 2) = 21通りあります。この場合は全てのビットが埋まりましたので、残りの"0"を挿入するステップが必要なくなります。"0"がないので"|||"の並び方と考えて計算しても、1通りという結果が得られます。
この考え方を使って、一般的な計算方法を考えてみましょう。 まず、長さnのビット列で隣り合う"1"の総数がkになるようなものの中で、"1"の数は(k+1)個が最小値です。このとき、m個の"1"を追加し、さらにm個の"0"を挿入して連続する"1"の並びを(m+1)個に分割します。
このとき、"1"の並びを分割する場合の数はC(k+m, m)であり、それぞれの場合に対して残りの"0"を挿入する場合の数はC(n-k-m, m+1)になります。したがって、
f(n, k) = C(k, 0) * C(n-k, 1) + C(k+1, 1) * C(n-k-1, 2) + C(k+2, 2) * C(n-k-2, 3) + ...
のように計算できます。
n=10, k=5の例なら、
f(10, 5) = C(5, 0) * C(5, 1) + C(6, 1) * C(4, 2) + C(7, 2) * C(3, 3) = 1 * 5 + 6 * 6 + 21 * 1 = 5 + 36 + 21 = 62
のようになります。
実装例
以上の方法でPythonのコードを書いてみました。
import sys from scipy.special import comb def solve(n, k): sum = 0 a = n - k b = k c = 0 while a >= c + 1: # exact=True で正確な整数値が得られる sum += comb(a, c + 1, exact=True) * comb(b, c, exact=True) a -= 1 b += 1 c += 1 return sum # テストケースの数 n_test = int(sys.stdin.readline()); for line in sys.stdin: tid, n, k = list(map(int, line.split())) print(f"{tid} {solve(n, k)}")
楽しい実装例
Cの実装
私の趣味はCで書かれたコードを短く書くことですので、実際に提出するコードをできるだけ短いCのコードに書き換えます。パッと見では組み合わせ計算の方が短く書けそうなので、これをまずCで書いてみます。
#include<stdio.h> int combination(int n, int k) { long long int a = 1; for(int i=1; i<=k; ++i) { a = a * n / i; --n; } return a; } int solve(int n, int k) { int sum = 0; int a = n - k; int b = k; int c = 0; while(a >= c + 1) { sum += combination(a, c + 1) * combination(b, c); a -= 1; b += 1; c += 1; } return sum; } int main() { // テストケースの数 int n_test; scanf("%d", &n_test); for(int i=0; i<n_test; ++i) { int tid, n, k; scanf("%d %d %d", &tid, &n, &k); printf("%d %d\n", tid, solve(n, k)); } return 0; }
長くなってしまいました(泣) というわけで、(POJ上で)ギリギリ動く範囲で省略できるものを省略していきます。
スッキリ書こう
f(n,k,m,j){ for(m=j=1;j<=k;--n,++j)m=1.*m*n/j; return m; } g(n,k,s,c){ n-=k; for(s=c=0;n>=c+1;--n,++k,++c)s+=f(n,c+1)*f(k,c); return s; } t,i,a,b; main(z){ for(;~scanf("%d",&b);a=b)--z%3||printf("%d %d\n"-!z,z/-3,g(a,b)); }
関数名をcombination->f, solve->gと書き換えました。それから変数の型を省略しました。全部int型です。とってもわかりやすいですね。しかし私は気に食わないんですよ。関数が3つもあることに!本当にひどいコードなので、main関数だけにしてしまいましょう。
関数っていらないよね
double x,j,u,w; g(n,k,s,c){ n-=k; for(s=c=0;n>=c+1;s+=x*(n-c)/j,--n,++k,++c) for(u=n,w=k,x=j=1;j<=c;++j,--u,--w)x=x*u/j*w/j; return s; } a,b; main(z){for(;~scanf("%d",&b);--z%3||printf("%d %d\n"-!z,z/-3,g(a,b)),a=b);}
ひとまず関数gの中にfを埋め込みました。組み合わせの掛け算をまとめて行うための精度確保に泣く泣くdoubleを使いました。本当に悲しいですが、とりあえずgに消えてほしいです。
double x; s,b,c,j,n,k,w; main(z){ for(;~scanf("%d",&b);--z%3?n=b:printf("%d %d\n"-!z,z/-3,s)) for(k=b,s=c=0;x=j=n-k>c++;s+=x*c/w) for(w=++k;j+~c;)x=x*--w/j*(n-k-j+2)/j++; }
だいぶスッキリしましたね!しかしまだまだ汚らしいコードに見えます。forって3回も書いてますし、doubleは本当に消えてほしい…。しかし現状私のスキルではこれくらいのサイズにしかできませんでした。空白文字や改行を取り除くと、このコードは166Bです。そしてこれより短いコードを書くことは可能です。よければ挑戦してみてください。
ところでコードゴルフってご存じですか?
あなたはコードゴルフをご存じですか?コードゴルフというのは、ソースコードをできるだけ短く書くという遊びです。「ソースコードを短く書く」⇒「少ない打鍵(ストローク)数でコードを書く」ということから、プログラミング上のゴルフと呼ばれています。
本稿の記事を読んで「ちょっと難しいなー」と思ったあなた!どうぞご安心ください。Anarchy Golf(通称あなごる)にはもっと簡単な問題もありますし、C以外の様々なプログラミング言語でコードゴルフを楽しむこともできます。
興味を持った方は是非是非ご参加ください!
きれいなPythonプログラミング
久しぶりに本出ます
なんとPython本です。Pythonに魂を売りました。ウソです。2月15日発売だそうです。
なんでPython本?
昨年なんとなく見て、面白かったので日本語版があると良いかなーと思って書いた次第です。Pythonに魂を売ったわけではないのですが、この4~5年くらい、仕事上でも研究上でもPythonでコードを書く機会が非常に増えました。機械学習が流行ったのと、(職業としての)プログラマー以外の人がプログラムを書くことが増えたからかなと個人的には感じています。
みんなプログラム書けるよね
最近感じるのは、特に若い人たちは皆普通にプログラミングできるということ。理工系の学部でない学生さんたちで、プログラミングのプの字も知らないような人でも、必要になってから2~3か月もあれば普通にコードを書いているし、いろんなツールが使えるようになっています。この10年くらいで初心者向けの学習環境が格段に良くなっていると思います。良いプログラミング本もたくさんありますからね。そんなわけで、今さら初心者用の本を書き下ろす気もないし、翻訳するのもそれほど気が進みません(めっちゃ良いのがあればやりたいですが)。
中~上級者の本はもっとあった方がいい
本書は、プログラミング初心者が「もうワンランク上」を目指すための内容です。たとえば、
- 本に書いていないエラーが出ることが多くなった
- 新しいライブラリを使うのにやたら手間取る
- 自分の書いたコードの量がかなり多くなった
- 複数人で開発する必要が出てきた
のような状況を経験するようになってくると、問題の解決方法や仕事の管理方法の質はとても重要になってきます。アルゴリズムとかデータ構造のような問題というよりは、実務のクオリティを上げる必要が出てきたときに、一度目を通しておくと良いのではと思います。
翻訳版
原著との違い
本題とあまり関係がないような細かい修正は加えてたものの、内容的には原著とほぼ同じです。原著が英語ということで参考文献がすべて英語のテキストや動画ですので、少しでも使い勝手が良いように日本語訳された資料があるものについてはその情報を記載しました。動画に関しては私が実際に動画をチェックして、日本語字幕の質が特に良く、観ていてストレスが少ないものにコメントを付けました。その他、ちょっと日本人にはわかりにくそうかなという部分には注釈をいれてあります。
訳文
翻訳というのは、私は結構最近まで、原文をできるだけ忠実に訳した方が良いと信じていました。しかしどうも世間的にはそうではなくて単純にわかりやすい方が良いっぽいので、原著の情報量はキープしつつ文章自体は結構書き換えた部分が多いです。もし本書を手に取っていただけた方がいらっしゃったら、何らかのフィードバックをいただけると大変ありがたいです。
あと近況も
半年前くらいに「大学院生になりましたー」と書きましたが、昨年の秋から休学しています。理由はメインの仕事+きれいなPython本で手一杯だったのと、研究が一段落したことです。これからジャーナルに最低2本採録される必要があって、論文作成~採録までの時間がちょっと見当つかなかったということもあって、休学中にある程度仕上げてから復学せねばと考えています。仕事しながらだとホントしんどいです。いや、しんどいことはわかっていたのだけど、思っていた以上に(精神的に)しんどい。社会人でドクター目指す人は入学する前から緻密に計画しといた方がよいですよ、まじで。
大学院生になりました
大学を卒業してから20年以上経ちますが、ようやくちゃんと勉強したいという気持ちが生まれました(遅) というわけで、事後報告になりますが2020年から再び学生になりました。学位論文が無事に完成するまで、もしかしたらものすごく時間がかかるかもしれないので、ひとまずお先に、私を受け入れてくださった関西大学大学院 総合情報研究科の諸先生方に心より感謝申し上げます。それから、お仕事お断りしちゃった方々本当に申し訳ないです。一通り終わったら何でもしますんで🙇♂️
博士後期課程
受験資格
私は大学院に進学後すぐに退学してしまったので、本来ならば前期課程から入学すべきなのですが、後期課程の受験資格審査という制度のおかげで受験資格を得ることができました。昔ちょこっと書いたショートペーパーとか、執筆系の仕事の評価が大きかった気がします。開発系の実績もそれなりに評価していただいたとは思いますが。
入学試験
入学試験の前の段階から結構な回数の面談を重ねてある程度準備はできていましたが、なんせ20数年ぶりの試験なのでかなり緊張しました。試験が始まって40~50分位で、周りの若い子たちの手が止まるんですよ。すごいスピードで解き終わってるんですよね。私はというと、いきなり解く問題を間違えて焦り、辞書をパラパラし過ぎて時間が無くなりで、冷や汗ダラダラの中90分時間ギリギリで完成しました。筆記試験が終わった安堵感から面接ではかなり注意散漫な感じだったと思いますが、なんとかクリアできました。
40過ぎて大学院の仕組みを知る
正直な話、生まれて40年くらいの間、大学院のことをよくわからないまま生きてました。研究会?国際会議?論文誌?ナニソレ的な。昔書いた論文も、当時はよくわからずに投稿し、よくわからんけど採録された感じですね。おまけに修士課程をスキップしたこともあって、去年一年間はそういうのを一通り理解するだけで終わったような気がします。早くも休学リーチがかかっている気が…。
何の研究すんの?
最適化とかアルゴリズムの研究にはめっちゃ興味ありますが、実際にやっているのはSNS(ほぼTwitter)に関してで、学位論文もTwitterに関するもので書く予定です。そもそもなんで関大なのかというと、偶然知り合って研究のお手伝いをすることがあった院生の方がご卒業ということで、彼の研究を引き継いでやっていくと内容もそれなりに把握できているし、ある程度方向性が決まっているので良いかなーという理由です。
自分自身、Twitterを使うのを長らく控えていて、それは忙しいということだけでなく使っててなんかしんどいというのが大きな理由です。便利だし面白いんだけど、この疲労感は辛いなと思っています。だから、もうちょっと楽に使えるようになりたいという気持ちもあって、Twitterに関する研究でやっていくと決めました。
今とこれから
とにかくやり切りたい
いろいろと自分を追い込んで疲れてきたので、息抜きにブログ書いたりTwitterで遊んだりしていこうと思います。心身の健康を保ちつつ、なんとか学位論文を完成させたい。将来どう役に立つとか二の次です。学位は足の裏に付いた飯粒みたいなものなんて言われたりしますが、今足の裏がベッタベタです。
辛いこと
大学院に入学すると決めてから、マラソンマッチやるのを断っているんですよ!通知が来るたびにムズムズしてます。やるべきことをすべて終わらせて、思う存分マラソンしたいです。
まあそんなわけで
皆さん今後ともよろしくお願いします。「そんなことより論文書け」とか言わないでね😱
256【解説】
本稿はCodeIQで2016年7月12日~2018年4月25日に出題された 【実力判定:Cランク】256 という問題の解答例と簡単な解説です。
- 本稿におけるコードは単なる解答の1例に過ぎません。「もっと良い解法があるよ!」とか、「こう書いた方がわかりやすいよ!」とか、「他の言語で書いてみたよ!」という場合は、自由にコメントに書いていただいても、個人のブログ等で公開していただいても結構です。
256【解説】
入力サイズが小さいので、素直に二重ループでよいでしょう。数値のリストから同じ要素を2回選ばないように注意してください。
# python3 # O(n^2) n = int(input()) v = [int(s) for s in input().split()] for i in range(n-1): for j in range(i+1, n): if v[i] + v[j] == 256: print("yes") exit() # 見つかったらおしまい # 見つからなければココに到達する print("no")
「2人組作って!」【解説】
本稿はCodeIQで2014年9月4日~2014年9月16日に出題された プログラミング言語★総選挙 予備選挙「2人組作って!」 という問題の解答例と簡単な解説です。
- 本稿におけるコードは単なる解答の1例に過ぎません。「もっと良い解法があるよ!」とか、「こう書いた方がわかりやすいよ!」とか、「他の言語で書いてみたよ!」という場合は、自由にコメントに書いていただいても、個人のブログ等で公開していただいても結構です。
「2人組作って!」【解説】
◆解説
欠席者が最大1という制約でペアを作る問題でした。欠席者が0か1であれば、次のようなルールで判別することができます。

生徒の位置によって、ABのグループに分けると、Aのグループの人数とBのグループの人数が等しくなった場合にペアを作ることができます。


の場合はAもBも4ずつになり、うまくペアを作ることができますが、

の場合はAが5でBが3となり、数が等しくなくなりますので、ペアを作ることができません。 この性質を利用すれば、単純に出席者をグループ毎に数えるだけで済みます。
# python3 import sys # index[x, y]について、x+yが偶数ならa、奇数ならbを増やす a = b = 0 for i, s in enumerate(sys.stdin): for j, c in enumerate(list(s)): # 1文字ずつ処理 if c == 'O': # 出席者 if i+j & 1 == 0: # indexの偶奇を調べる a += 1 else: b += 1 print("yes" if a == b else "no")